- 01
2016年DeepMind团队(google旗下)的AlphaGo(一个围棋的AI)以4:1战胜顶尖人类职业棋手李世石。她到底是怎么下棋的?

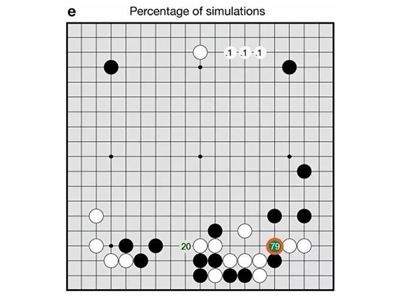
AlphaGo在面对当前棋局时,她会模拟(推演棋局)N次,选取“模拟”次数最多的走法,这就是AlphaGo认为的最优走法。
例如图中,所有没有落子的地方都是可能下子的,但在模拟中,右下那步走了79%次,就选那一步了,就那么简单。后面你会发现,“模拟”次数“最多”的走法就是统计上“最优”的走法。
1、啥是模拟?
模拟就是AlphaGo自己和自己下棋,相当于棋手在脑袋中的推演,就是棋手说的“计算”。
AlphaGo面对当前局面,会用某种(下面会讲)策略,自己和自己下。其中有两种策略:往后下几步(提前终止,因为AlphaGo有一定判断形势的能力);或者一直下到终局(终局形势判断相对简单,对于棋手简单,对于机器还有一定难度,但是这个问题已经基本解决)。对于棋手来说就是推演棋局。
AlphaGo会模拟多次,“不止一次”。越来越多的模拟会使AlphaGo的推演“越来越深”(一开始就1步,后来可能是几十步),对当前局面的判断“越来越准”(因为她知道了后面局面变化的结果,她会追溯到前面的局面,更新对前面局面的判断),使后面的模拟“越来越强”(更接近于正解,她后面模拟出来的着法会越来越强)。怎么做到的?看她怎么模拟的。
注意,这里的模拟是下棋(线上)时的模拟,后面还会有个学习时的模拟,不要混淆了。
2、AlphaGo怎么模拟的?
每次模拟中,AlphaGo自己和自己下。每步中由一个函数决定该下哪一步。函数中包括了以下几个方面:这个局面大概该怎么下(选点:policy net),下这步会导致什么样的局面,我赢得概率是多少(形势判断:value net 和rollout小模拟),鼓励探索没模拟过的招法。这些英文名词后面会有解释。
模拟完一次后,AlphaGo会记住模拟到棋局,比如几步以后的棋局。并且计算这时policy,value。因为这时已经更接近终局了,这时的值会更加准确(相对于前面的模拟或局面)。AlphaGo还会用这些更准的值更新这个函数,函数值就越来越准了,所以模拟的每一步越来越接近正解(最优的下法),整个模拟越来越接近黑白双方的最优下法(主变化,principle variation),就像围棋书上的正解图一样。到此为止,你已经大概了解AlphaGo她怎么工作的了,下面只是一些细节和数学了。
3、那个函数是啥,好神奇?
这个函数,分为两个部分。
Q是action value, u是bonus。Q其实就是模拟多次以后,AlphaGo计算走a这步赢的概率,其中会有对未来棋局的模拟(大模拟中的小模拟),和估计。u中包括两个部分。一方面根据局面(棋形)大概判断应该有那几步可以走,另一方面惩罚模拟过多的招法,鼓励探索其他招法,不要老模拟一步,忽略了其他更优的招法。
4、Q(action value)具体是什么?

Q看上去有点复杂,其实就是模拟N次以后,AlphaGo认为她模拟这步赢得平均概率。
分母N是模拟这步棋的次数。
分子是每次模拟赢的概率(V)的加和。
其中V又包括两部分,value net对形势的判断。和一个快速模拟到终局,她赢的概率。
value net是说她看这个这个局面,就要判断赢的概率,“不准”往下几步想了。value net下面详细讲。
快速模拟是说她看这个这个局面,自己和自己下完,看看黑白谁赢的概率高。快速模拟是我们这个大模拟中的一个小模拟。
Q就是看当下(value net),也看未来(快速模拟),来决定怎么模拟(对人来说就是往哪里想,对于棋手就是思考哪些可能的着法),下棋方(模拟中下棋方黑白都是AlphaGo)下那一步赢的概率高,从而决定模拟下那一步。
5、u(bonus)具体是啥?
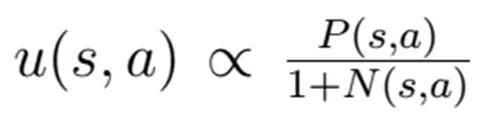
u中包括两个部分。
分子是AlphaGo根据当前局面判断(policy net),不模拟,比如棋手根据棋形大概知道应该有哪几步可以走。
分母是模拟到现在走当前步的累加,越大下次模拟越不会走这了。
一句话,(Q+u)就是决定模拟中,下棋方会走(模拟)哪里。
到此,我们大概了解了AlphaGo的两大神器:value net(形势判断:模拟中,我走这步,我赢的概率是多少)和policy net(选点:模拟中,这个局面我走那几步最强)。下面会揭开他们神秘的面纱。
6、为什么选模拟次数最多的一步?
根据以上的函数可知,模拟次数最多一步,其实就是在多次模拟中,AlphaGo认为那一步最可能赢的次数的累加(或平均,除以总模拟次数)。
7、为什么要分为policy net(选点)和value net(形势判断)呢,选点和形势判断不是一个东西吗?
确实,选点和形势判断是互相嵌套的。首先,围棋的形势判断是非常困难的。在围棋直播中我们经常看到,职业9段也不能准确判断当前局面,除非地域已经确定,没有什么可以继续战斗的地方,一般也就是接近终局(官子阶段)。即使职业棋手,选点和判断也是定性的成分偏多,定量的成分偏少。以前说中国顶级棋手古力能推演到50步,已经非常强了。
再说嵌套问题,准确的定量的选点和判断,就要计算(对于棋手是在脑子里推演,对于机器就是模拟)才行。在推演中,我选点走那步决定于,走这步后我赢的概率,而这个概率又决定于对手走那一步(我会假设对手弈出她最强的一步,对我最不利),对手走那一步决定于,她走那步后,她对形势的判断要对她最好,这又取决于我的下下步(第3步了)走哪里(对手她也会假设我会下出对她最不利的一步,自然对我最优),从而不断的嵌套,这个“死结”要到终局(或者接近)才能解开(终局形势判断比较简单)。所以不到终局,判断形势是非常困难的,即使职业的9段也不行。这就是围棋比象棋难的关键所在,它没有简单的形势判断的方法,而象棋有。
要回答这个问题7还要看下面了。
8、AlphaGo是怎么打开这个死结的?
AlphaGo没有进行直接的形势判断,就是没有直接学习value net,而是先做一个选点(policy net)程序。选点可以认为是一个时序(走棋)的一个局部问题,就是从当前局面大概判断,有哪几步可能走,暂时不需要推演(那是模拟的工作)。棋手的选点是会推演的,这里的基础policy net是不推演的,前已经看到AlphaGo线上模拟中选点(Q+u)是有推演的。
所以policy net是用在“每次模拟”中,搜索双方可能的着法,而最优步的判断是“N次模拟”的任务,policy net不管。此外policy net还用来训练value net,也就是说,value net是从policy net 来的,先有policy 才有value。
选点(policy net)能成立吗?如果不成立,也是没用。
9、第一神器policy net怎么工作的?
先大概看下这个图。现在轮到黑棋下,图上的数字是AlphaGo认为黑棋应该下这步的概率。我们还发现,只有几步(2步在这个图中)的概率比较大,其他步可能性都很小。这就像职业棋手了。学围棋的人知道,初学者会觉得那里都可以走,就是policy(选点)不行,没有选择性。随着棋力增长,选择的范围在缩小。职业棋手就会锁定几个最有可能的走法,然后去推演以后的变化。
AlphaGo通过学习,预测职业选手的着法有57%的准确率。提醒一下,这还是AlphaGo“一眼”看上去的效果,她没开始推演(模拟)呢。而且她没预测对的着法不一定比职业棋手差。

policy net怎么学习的,学啥???
首先,policy net是一个模型。它的输入时当前的棋局(19*19的棋盘,每个位置有3种状态,黑,白,空),输出是最可能(最优)的着法,每个空位都有一个概率(可能性)。幸运的是,着法不像形势判断那么无迹可寻。我们人已经下了千年的棋。policy net先向职业选手学习,她从KGS围棋服务器,学习了3000万个局面的下一步怎么走。也就是说,大概职业选手怎么走,AlphaGo她已经了然于胸。学习的目的是,她不是单纯的记住这个局面,而是相似的局面也会了。当学习的局面足够多时,几乎所有局面她都会了。这种学习我们叫做“监督学习”(supervised learning)。以前的职业棋手的棋谱,就是她的老师(监督)。
AlphaGo强的原因之一是policy net这个模型是通过深度学习(deep learning)完成的。深度学习是近几年兴起的模拟人脑的机器学习方法。它使AlphaGo学习到的policy更加准确。以前的AI都没有那么强的学习能力。
更加厉害的是,AlphaGo从职业棋手学完后,感觉没什么可以从职业棋手学的了。为了超越老师和自己,独孤求败的她只能自己左右互搏,通过自己下自己,找到更好的policy。比如说,她从监督学习学到了一个policy,P0。
AlphaGo会例外做一个模型P1。P1一开始和P0一样(模型参数相同)。稍微改变P1的参数,然后让P1和P0下,比如,黑用P1,白用P0选点,直到下完(终局)。模拟多次后,如果P1比P0强(赢的多),则P1就用新参数,否则,重新再原来基础上改变参数。我们会得到比P0强一点点的P1。注意,选点是按照policy的概率的,所以每次模拟是不同的。多次学习后AlphaGo会不断超越自己,越来越强。这种学习我们叫做增强学习(reinforcement learning)。它没有直接的监督信息,而是把模型发在环境中(下棋),通过和环境的互相作用,环境对模型完成任务的好坏给于反馈(赢棋还是输),从而模型改变自己(更新参数),更好的完成任务(赢棋)。增强学习后,AlphaGo在80%的棋局中战胜以前的自己。
最后,AlphaGo还有一个mini的policy net,叫rollout。它是用来上面所说的模拟中,快速模拟的终局的。它的输入比正常policy net小,它的模型也小,所以它的耗时是2微妙,而一个policy要3毫秒。它没有policy准,但是它快。
总结一下policy。它是用来预测下一步“大概”该走哪里。它使用了深度学习,监督学习,增强学习等方法。它主要用于每次模拟中的bonus的先验(我大概该怎么走),和value net的学习(后面的重点)。
如果单纯用policy预测的着法来作为最优着法,不通过value net的计算和上面说的模拟,对职业棋手那是不行的。但是,单纯用policy预测已经足够打败以前的围棋AI(大约有业余5段实力)了。这说明了上面3种学习方法的强大威力。
AlphaGo就看了一眼,还没有推演,你们就败了。policy net为解开那个死结走出了第一步,下面我们就讲讲这第二个“神器”:value net。
10、第二神器value net怎么工作的?
前面说了,形势判断是什么无迹可寻,就连职业9段也做不到。有了policy net,整个世界都不一样了。AlphaGo她的灵魂核心就在下面这个公式里。
V*(s)=Vp*(s)约等于Vp(s)。
s是棋盘的状态,就是前面说的19*19,每个交叉3种状态。
V是对这个状态的评估,就是说黑赢的概率是多少。
V*是这个评估的真值。
p*是正解(产生正解的policy)
p是AlphaGo前面所说学到的最强的policy net。
如果模拟以后每步都是正解p*,其结果就是V*,这解释了等号。
如果你知道V*这个函数,在当前局面,你要对走下一步(围棋平均有250种可能性)后的状态s进行评估,选最大的V*走就行。围棋就完美解决了。但是,前面说了,V*不存在。同样p*也不存在(理论上存在,实际因为搜索空间太大,计算量太大找不到。在5*5的棋盘中下棋可以做到)。
AlphaGo天才般的用最强poilicy,p来近似正解p*,从而可以用p的模拟Vp来近似V*。即使Vp只是一个近似,但已经比现在的职业9段好了。想想她的p是从职业选手的着法学来的,就是你能想到的棋她都想到了。而且她还在不断使的p更准。顶尖职业棋手就想以后的20-40步,还会出错(错觉)。AlphaGo是模拟到终局,还极少出错。天哪,这人还怎么下。
围棋问题实际是一个树搜索的问题,当前局面是树根,树根长出分支来(下步有多少可能性,棋盘上的空处都是可能的),这是树的广度,树不断生长(推演,模拟),直到叶子节点(终局,或者后面的局面)。树根到叶子,分了多少次枝(推演的步数)是树的深度。树的平均广度,深度越大,搜索越难,要的计算越多。围棋平均广度是250,深度150,象棋平均广度是35,深度80。如果要遍历围棋树,要搜索250的150次方,是不实际的。这也是围棋比象棋复杂的多的原因之一。但更重要的原因前面讲了:是象棋有比较简单的手工可以做出的value函数。比如,吃王(将)得正无穷分,吃车得100分,等等。1997年打败当时国际象棋世界冠军的DeepBlue就是人手工设计的value。而围棋的value比象棋难太多了。手工根本没法搞。又只能靠深度学习了。
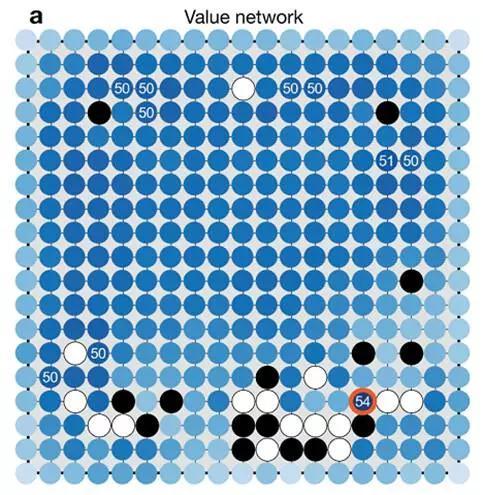
在讲value的原理前,先看看定性看看value的结果。如图,这是AlphaGo用value net预测的走下一步,她赢的概率。空的地方都被蓝色标示了,越深说明AlphaGo赢的概率越高。这和我们学的棋理是相符的,在没有战斗时,1,2线(靠边的地方)和中间的概率都低,因为它们效率不高。而且大多数地方的概率都接近50%。所以说赢棋难,输棋也很难。这当然排除双方激烈战斗的情况。
这里讲讲怎么通过policy net 得到value net。有了policy,value就不是那么难以捉摸了,死结打开了。AlphaGo可以模拟(自己和自己下,黑白都用最强的policy),直到终局。注意,这里的模拟和最初说的模拟有点不同。最初的模拟是AlphaGo在下棋(线上)中用的,用来预测。这里的模拟是她还在学习(线下)呢。终局时V*(谁赢)就比较容易判断了。当然,对机器来说也不是那么容易的,但相对于中局来说是天渊之别。
value net也是一个监督的深度学习的模型。多次的模拟的结果(谁赢)为它提供监督信息。它的模型结构和policy net相似,但是学的目标不同。policy是下步走哪里,value是走这后赢的概率。
总结一下,value net预测下一走这后,赢的概率。本身无法得到。但是通过用最强policy来近似正解,该policy的模拟来近似主变化(就围棋书上那个,假设书上是对的),模拟的结果来近似准确的形势判断V*。value net用监督的深度学习去学模拟的得到的结果。value net主要用于模拟(在线,下棋的时候)时,计算Q值,就是平均的形势判断。
再回顾一下模拟,模拟的每一步是兼顾:模拟到现在平均的形势判断value net,快速rollout模拟到终局的形势判断,根据当前形势的选点policy,和惩罚过多的模拟同一个下法(鼓励探索)等方面。经过多次模拟,树会搜索的越来越广,越来越深。由于其回溯的机制,Q值越来越准,下面的搜索会越来越强。因为每次的Q值,都是当前模拟认为的最优(排除鼓励探索,多次后会抵消),模拟最多的下法(树分支)就是整个模拟中累积认为最优的下法。
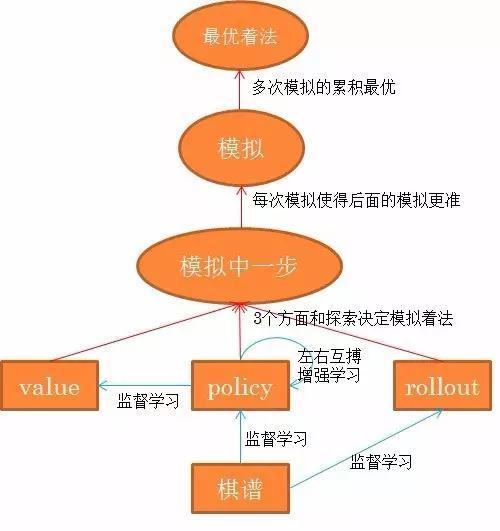
到此为止,AlphaGo她神秘的面纱已经揭开。她的基本框架见下图。下棋时的线上过程是图中红箭头。线下的准备工作(学习过程)是蓝箭头。。再串一下。AlphaGo下棋(线上)靠模拟,每次模拟要选下那一步,不是简单的选点policy就完了,而是要参考以前模拟的形势判断,包括:value net和快速模拟(小模拟)到终局,鼓励探索,policy(先验),就是(Q+u),它比单纯的policy准。她选择模拟最多的下法(就是平均最优)。这是线上,下着棋了。之前(线下),她要训练好policy模型,rollout模型和value 模型。其中,policy,rollout可以从棋谱,和自己下棋中学到。value可以从用学好的policy下棋的模拟结果监督学到。从而完美解决value学不到的问题和policy和value互相嵌套的死结。从棋谱直接学value net现在还不行。
11、AlphaGo用到哪些技术?
AlphaGo在树搜索的框架下使用了深度学习,监督学习和增强学习等方法。
以前最强的围棋AI使用蒙特卡洛树搜索的方法。蒙特卡洛算法通过某种“实验”的方法,等到一个随机变量的估计,从而得到一个问题的解。这种实验可以是计算机的模拟。让我们看看蒙特卡洛树搜索怎么模拟的。算法会找两个围棋傻子(计算机),他们只知道那里可以下棋(空白处,和非打劫刚提子处),他们最终下到终局。好了,这就可以判断谁赢了。算法就通过模拟M(M>>N)盘,看黑赢的概率。可以看到这明显的不合理。因为每步是乱下的。有些棋根本就不可能。即使如此,这个算法可以达到业余5段左右水平。
AlphaGo可不是乱下,她是学了职业棋手着法的。所以AlphaGo的搜索叫beam search(只搜索几条线,而不是扫一片)。前面也可以看到AlphaGo认为的可能着法就几种可能性,而不是随机的250种。这就是从250的150次方到几(<10)的n(n<<150,可以提前终止搜索,因为有value net)次方,的计算量降低。虽然AlphaGo每次模拟的时间更长(因为要深度模型的预测policy和value,不是乱下),但是AlphaGo的模拟次数可以更少,是蒙特卡洛树搜索的1/15000。就是说AlphaGo的搜索更有目的性了,她大概知道该走哪里。解说说她下棋更像人了。我会说她下棋更像职业棋手,甚至超过职业棋手。线下的学习使得她的行为(模拟)有了极强的目的性,从而完成最终目标(赢棋)。
12、什么是打劫?
打劫,是指黑白双方都把对方的棋子围住,这种局面下,如果轮白下,可以吃掉一个黑子;如果轮黑下,同样可以吃掉一个白子。因为如此往复就形成循环无解,所以围棋禁止“同形重复”。根据规则规定“提”一子后,对方在可以回提的情况下不能马上回提,要先在别处下一着,待对方应一手之后再回“提”。如图中的情况:
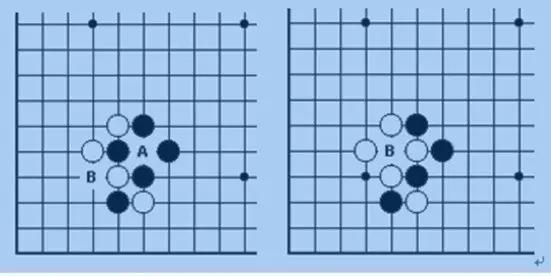
打劫因为反复走同一个点,会使搜索树的深度加大,而且因为其他位置劫才会影响劫的输赢,劫才之间又相互影响,有可能打劫中又产生新的劫。总之,打劫规则会使围棋的复杂度加大。
因为前两局棋没有下出打劫,有人会怀疑DeepMind和李世石有不打劫协议。在后面的棋局中,AlphaGo确实下出了主动打劫。而且从算法层面看,打劫也不会是她的模拟框架崩溃(可能会有一些小麻烦)。
13、遇强则强,遇弱则弱?
AlphaGo的表现似乎是遇强则强,遇弱则弱。这可能是由于她的学习监督信息决定的。policy和value学习时,和rollout模拟时,最后的结果是谁赢(的概率),而不是谁赢“多少”(赢几目)。所以在AlphaGo领先时(几乎已经是常态了),她不会下出过分的棋,她只要保证最后赢就行了,而不是像人一样要赢的多,赢的漂亮。即使有杀大龙(一大块棋)的机会,她也不一定杀,而是走温和的棋,让你无疾而终。估计只有在AlphaGo判断她大大落后的时候,她才会冒险走过分的棋(这好像不常见)。
14、AlphaGo下棋为什么花钱?
AlphaGo有单机版,多机(分布式)。分布式明显比单机强。去年的分布式有40个搜索线程,1202个CPU,176个GPU(显卡)。和李世石下棋时可能更多。这么多机器的运作和维护就是烧钱。
15、AlphaGo有漏洞吗?
AlphaGo解决的是一个树搜索问题,并不是遍历所有着法的可能性,她的着法只是接近正解,不是一定正解。
最简单的人战胜AlphaGo的方法就是改规则,比如扩大棋盘。人类能比较简单的适应,搜索空间增大,AlphaGo不一定能适应。
就现有状况来说,棋手可以主要攻击AlphaGo模拟中的着法选择函数a。比如尽量下全局互相牵扯的棋(多劫,多块死活),就是尽量是中盘局面复杂,不要搞一道本(一条路走到底)局部的着法,当然,这对职业选手也不简单。
16、AlphaGo有哪些技术突破,使她能战胜人类顶尖棋手?
⑴继承了蒙特卡洛树搜索的框架进行模拟。
⑵在学习policy中使用了监督学习,有效的利用现有的棋手的棋谱,学到了他们的选点策略。
⑶在学习policy中使用了增强学习,从左右互搏中提高自己。
⑷利用policy net(选点模型)近似正解,用policy net的对弈的结果模拟正解对弈的结果,即正确的形势判断,从而打破形势判断和选点相互嵌套的死结。就是先学policy,再学value。
⑸在学习policy, value, rollout中使用深度学习模型。深度学习有非常强的学习能力。使得选点和形势判断前所未有的准(对比蒙特卡洛是随机选点,现在是职业棋手帮她选点了)。因为在每次模拟中用到了这两个“准”,使得在树搜索(就是推演)的过程更有目的性(树大量减枝,只模拟比较优良的下法)
⑹当然还有机器一贯的优势,不疲劳,不受心理情绪影响,不会错的记忆力等等。











点击排行

- 2 排行
- 3 排行
- 4 排行
- 5 排行
- 6 排行
- 7 排行
- 8 排行
- 9 排行
- 10 排行
